Estructura de pestañas
La configuración de datos de verificación se compone de dos pestañas:- General
- Duplicados y gestión de envíos
Opciones relacionadas con conversión y almacenamiento de datos
- Traducción automática al inglés de nombres de submission
- Eliminación parcial de datos
- Custom DI (Duplicate Information)
General
Configure las opciones relacionadas con conversión y almacenamiento de datos.
Traducción automática al inglés de nombres de submission
El texto de los IDs enviados se convierte al inglés para su visualización y almacenamiento.
Escenarios de usoCuando se prestan servicios globales, los IDs en diversos idiomas pueden unificarse en inglés para facilitar la gestión y la búsqueda de datos.
Eliminación parcial de datos
Cuando un Submission enviado se elimina, la información personal se borra y solo se mantiene información desidentificada.
Uso de la eliminación parcial de datosSe utiliza cuando desea eliminar Submissions para cumplir leyes de protección de privacidad pero manteniendo datos desidentificados para fines estadísticos y analíticos. Los datos eliminados no pueden recuperarse, así que configure con cuidado.
Custom DI (Duplicate Information)
Puede combinar libremente DI (Duplicate Information) para configuraciones adicionales. Si los datos no se recopilan tras la configuración, el DI no se genera.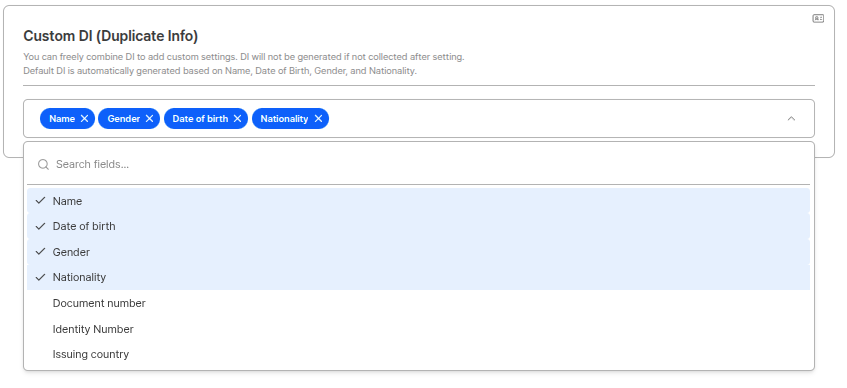
Default DIEl Default DI se genera automáticamente basándose en nombre/fecha de nacimiento/género/nacionalidad/retrato (cara en ID). Custom DI permite una detección de duplicados más detallada combinando campos adicionales al default DI.
Condiciones de generación de DIEl valor DI se genera solo cuando nombre, fecha de nacimiento, género, nacionalidad y retrato, etc. se proporcionan todos. Si la identidad de un remitente ha sido verificada a través del servicio ARGOS Identity, el valor DI existente se mantiene incluso cuando se autentica en un proyecto diferente.
Duplicados y gestión de envíos
Configure las opciones relacionadas con duplicate check pipeline y restricciones de submission.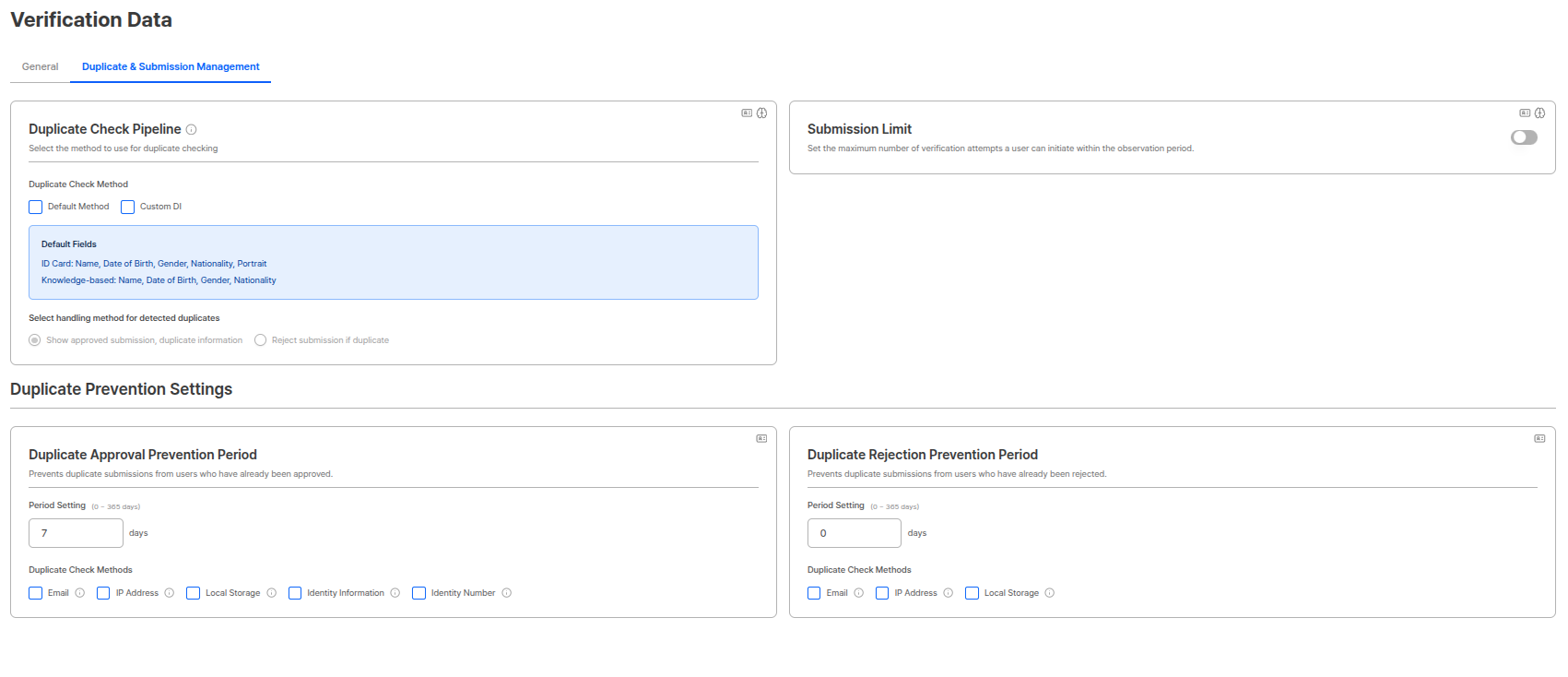
Duplicate Check Pipeline
Seleccione el pipeline a usar para las comprobaciones de duplicados. Tanto el método predeterminado como los pipelines de custom DI pueden seleccionarse, y se usa el valor duplicado del primer pipeline detectado durante la detección.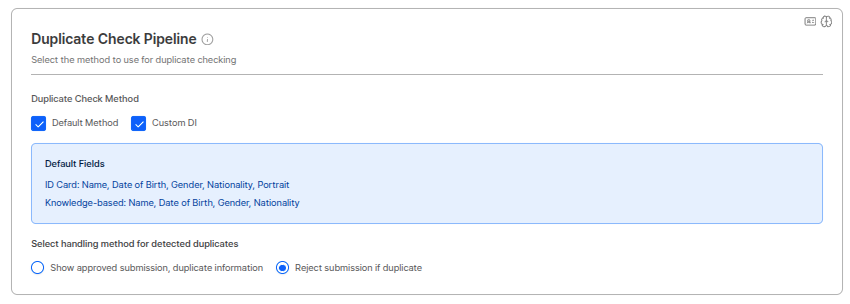
Selección de pipeline
Seleccione el pipeline para realizar comprobaciones de duplicados. Ambos pipelines pueden seleccionarse y pueden marcarse/desmarcarse con checkboxes.| Pipeline | Descripción |
|---|---|
| Default Method | Pipeline que detecta duplicados basándose en campos predeterminados. |
| Custom DI | Pipeline que detecta duplicados basándose en custom DI. |
Método de operación del pipelineCuando se seleccionan tanto el método predeterminado como los pipelines de custom DI, ambos se ejecutan simultáneamente. Se usa el valor duplicado del pipeline donde se encuentra primero el duplicado durante la detección.
Operación del pipeline del método predeterminado
El pipeline del método predeterminado funciona como una función de filtro al detectar usuarios duplicados usando DI, y comprueba duplicados en el siguiente orden al buscar en la base de datos: Orden de búsqueda en BD:- Exact Matching (coincidencia exacta)
- Fuzzy Matching (coincidencia similar)
- Compare Face (comparación facial)
| Etapa de filtro | Campos usados | Descripción |
|---|---|---|
| Exact Matching | Fecha de nacimiento (birthDate), Género, Nacionalidad | Busca usuarios con información que coincide exactamente. |
| Fuzzy Matching | Nombre | Busca usuarios con nombres similares. Permite errores tipográficos o diferencias menores. |
| Compare Face | Retrato | Confirma si es la misma persona comparando imágenes faciales. |
Condiciones de paso del filtroCuando se encuentra un usuario que cumple las condiciones en cada etapa de filtro, se procede a la siguiente etapa. Solo cuando se pasan todas las etapas se determina como usuario duplicado, por lo que los casos donde solo parte de la información coincide no se detectan como duplicados.
Campos predeterminados
Los campos predeterminados usados para comprobaciones de duplicados por pipeline son los siguientes:| Pipeline | Campos base |
|---|---|
| ID document | Nombre, fecha de nacimiento, género, nacionalidad, retrato |
| Knowledge-based | Nombre, fecha de nacimiento, género, nacionalidad |
Procesamiento al detectar duplicados
Seleccione el método de procesamiento para submissions detectados como duplicados. (Radio button)| Método de procesamiento | Descripción |
|---|---|
| Approved submission + Duplicate information display | Aprueba submissions detectados como duplicados pero muestra información de duplicado. |
| Reject submission if duplicate | Rechaza submissions cuando se detectan como duplicados. |
Uso del Duplicate Check PipelineCuando opera una política de una persona-una cuenta, puede activar el duplicate check pipeline para prevenir la creación de múltiples cuentas con la misma información de identidad. Seleccionar tanto el método predeterminado como los pipelines de custom DI permite una detección de duplicados más precisa.
Submission Rate Limiting
Establece el número máximo de intentos de verificación que un usuario puede realizar dentro del mismo periodo. Opera con el método Window Sliding para bloquear efectivamente intentos excesivos de submission por usuarios maliciosos.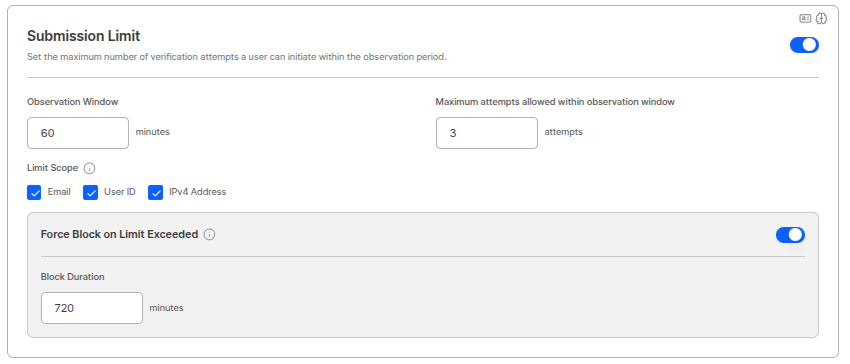
Método de operación (Window Sliding)
Submission rate limiting opera con el método Window Sliding. Basándose en cuándo llegó el último submission, retrocede por la ventana de tiempo establecida (Window) y comprueba el número de submissions dentro de ese periodo. Principio de operación:- El usuario intenta un submission.
- El sistema retrocede por la ventana de tiempo establecida (p. ej., 1 hora) desde el punto del último submission.
- Comprueba el número de submissions dentro de esa ventana de tiempo.
- Si se excede el conteo permitido, bloquea la autenticación por el tiempo restante de la ventana.
Configuración del alcance de restricción
Puede seleccionar los criterios para detectar submission rate limiting. Los siguientes elementos pueden combinarse:| Criterio | Descripción |
|---|---|
| Limita basándose en el número de submissions con la misma dirección de email. | |
| User ID | Limita basándose en el número de submissions con el mismo user ID. |
| IPv4 Address | Limita basándose en el número de submissions desde la misma dirección IPv4. |
Combinación del alcance de restricciónSe pueden seleccionar múltiples criterios simultáneamente. Por ejemplo, si se seleccionan tanto email como dirección IPv4, el bloqueo ocurre si cualquiera de los criterios excede el conteo permitido.
Función de bloqueo forzado
Puede bloquear efectivamente a abusadores mediante la función de bloqueo forzado cuando se exceden los límites. Configuración del periodo de bloqueo: Puede establecer un periodo de bloqueo adicional para usuarios que exceden el conteo límite. Durante este periodo, el usuario no puede intentar autenticación. Escenarios de uso:- Bloqueo de abusadores: Bloquee usuarios que intentan submissions continuamente con propósitos maliciosos
- Prevención de intentos malintencionados: Bloquee intentos repetidos de submission con propósitos de falsificación o fraude
- Protección del sistema: Prevenga la carga del sistema por submissions excesivos
Duplicate Approval Prevention Period
Previene submissions duplicados de usuarios ya aprobados.
Configuración de periodo
El periodo puede establecerse en un rango de 0~365 días. (Ejemplo: 7 días)Método de comprobación de duplicados
Comprueba duplicados basándose en los siguientes elementos. (Checkboxes)- Dirección IP
- Local storage
- Información de identidad: nombre, fecha de nacimiento, género, nacionalidad
- Número de registro de residente
Uso del Duplicate Approval Prevention PeriodSi opera una política de una persona-una cuenta ‘aprobada’, asegúrese de configurar esta función. Si existe un submission aprobado con la misma información dentro del periodo establecido, los nuevos submissions se rechazan.
Precauciones sobre campos de comprobación de duplicadosCuando Identity info e Identity number están configurados, los usuarios que envían información idéntica son rechazados.
Duplicate Rejection Prevention Period
Previene submissions duplicados de usuarios ya rechazados.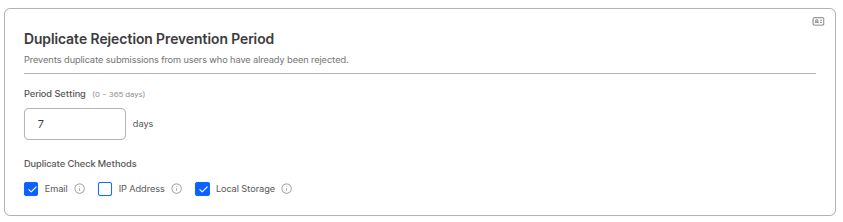
Configuración de periodo
El periodo puede establecerse en un rango de 0~365 días. (Ejemplo: 0 días)Método de comprobación de duplicados
Comprueba duplicados basándose en los siguientes elementos. (Checkboxes)- Dirección IP
- Local storage
Uso del Duplicate Rejection Prevention PeriodSe usa para prevenir que usuarios maliciosos reenvíen continuamente con información rechazada. Establecer el periodo en 0 días desactiva esta función.
Documentación relacionada
KYC Process
Consulte las políticas básicas de autenticación.
Refuerzo de autenticación y prevención de falsificación
Consulte la configuración de prevención de falsificación.
Lista de submissions
Aprenda a gestionar submissions.
GET/Submission API
Aprenda a usar la API para consultar valores DI.