Tab Structure
Verification data settings consist of two tabs:- General
- Duplicate and Submission Management
Data conversion and storage related options
- Automatic English translation of submission names
- Partial data deletion
- Custom DI (Duplicate Information)
General
Set data conversion and storage related options.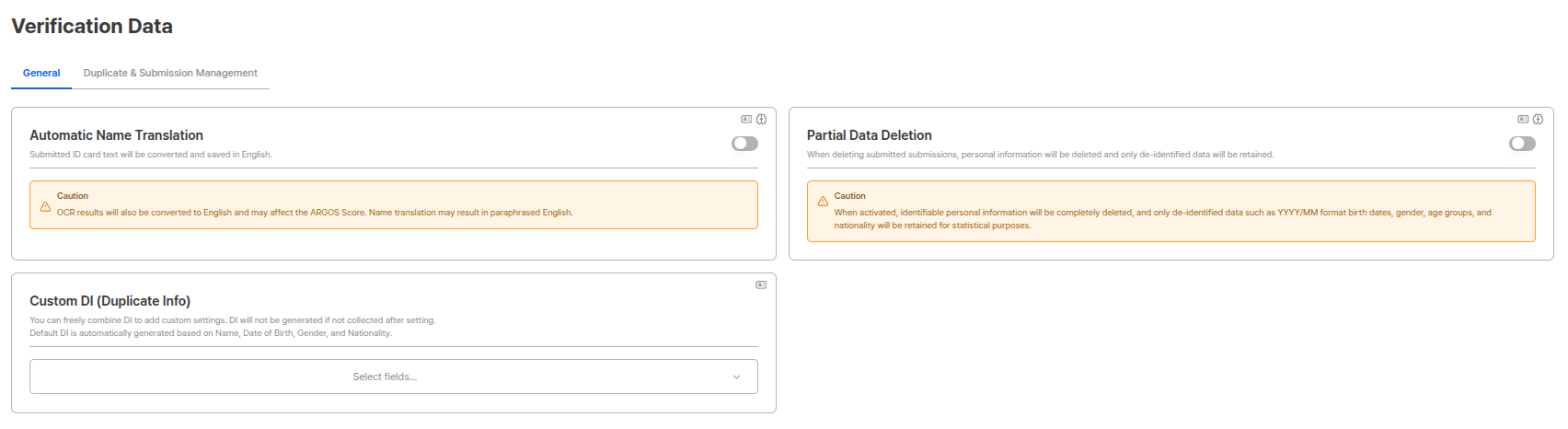
Automatic English Translation of Submission Names
Text from submitted IDs is changed to English for display and storage.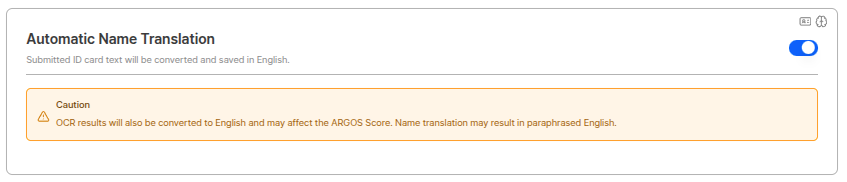
Usage ScenariosWhen providing global services, IDs in various languages can be unified to English to facilitate data management and search.
Partial Data Deletion
When a submitted Submission is deleted, personal information is deleted and only de-identified data is maintained.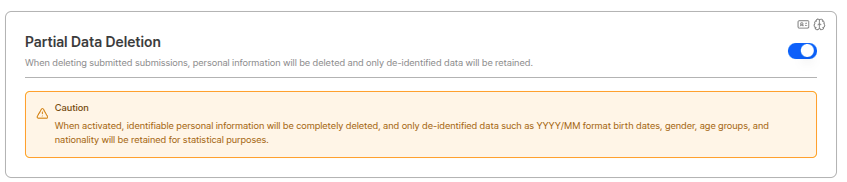
Partial Data Deletion UsageUsed when you want to delete Submissions for privacy protection law compliance but maintain de-identified data for statistical and analysis purposes. Deleted data cannot be recovered, so set carefully.
Custom DI (Duplicate Information)
You can freely combine DI (Duplicate Information) for additional settings. If not collected after setting, DI is not generated.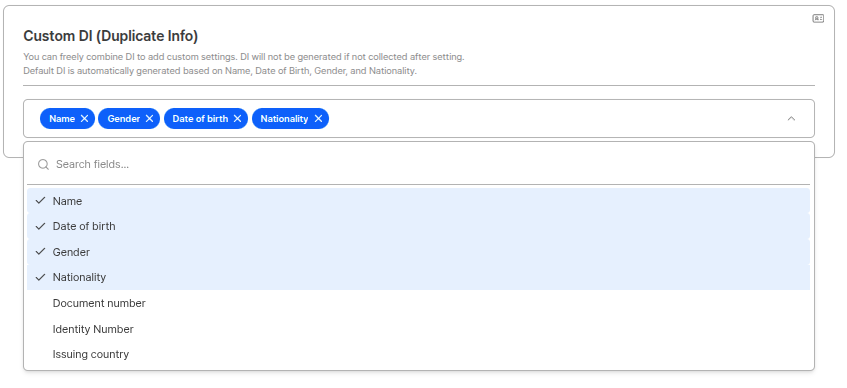
Default DIDefault DI is automatically generated based on name/date of birth/gender/nationality/portrait (face on ID). Custom DI allows more detailed duplicate detection by combining fields in addition to default DI.
DI Generation ConditionsDI value is generated only when name, date of birth, gender, nationality, and portrait, etc. are all provided. If a submitter’s identity has been verified through ARGOS Identity service, the existing DI value is maintained even when authenticated in a different project.
Duplicate and Submission Management
Set duplicate check pipeline and submission restriction related options.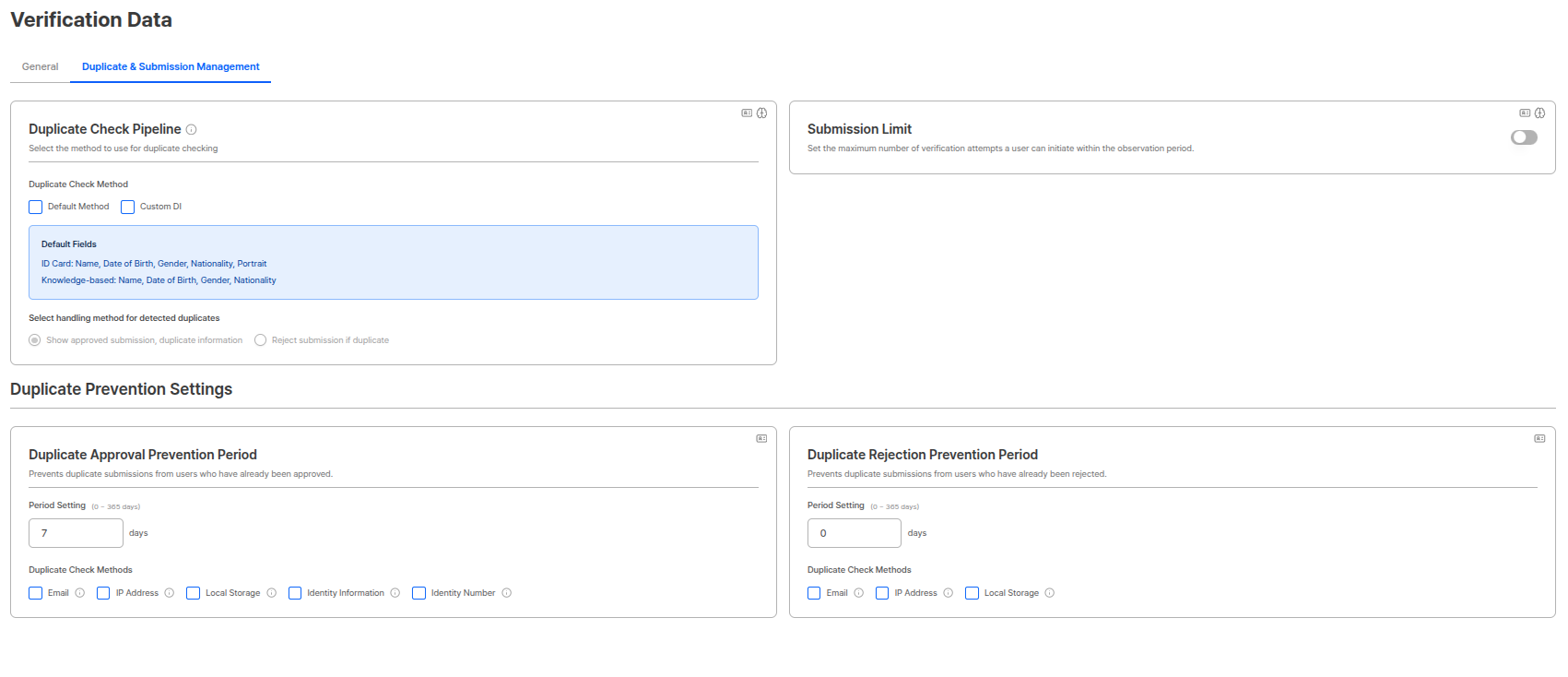
Duplicate Check Pipeline
Select the pipeline to use for duplicate checks. Both default method and custom DI pipelines can be selected, and the duplicate value from the first detected pipeline during detection is used.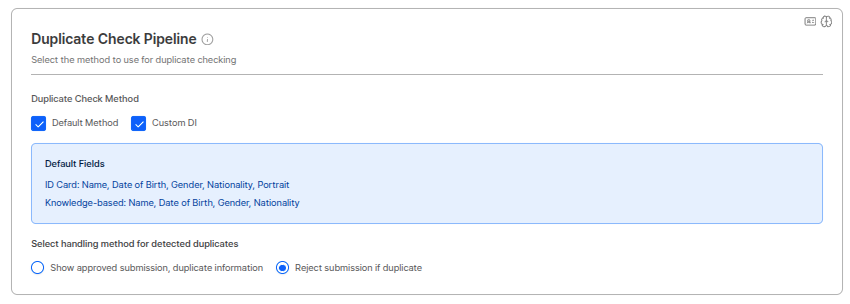
Pipeline Selection
Select the pipeline to perform duplicate checks. Both pipelines can be selected, and can be checked/unchecked with checkboxes.| Pipeline | Description |
|---|---|
| Default Method | Pipeline that detects duplicates based on default fields. |
| Custom DI | Pipeline that detects duplicates based on custom DI. |
Pipeline Operation MethodWhen both default method and custom DI pipelines are selected, both pipelines run simultaneously. The duplicate value from the pipeline where duplicate is first found during detection is used.
Default Method Pipeline Operation
The default method pipeline proceeds as a type of filter function when detecting duplicate users using DI, and checks for duplicates in the following order when searching the database: DB Search Order:- Exact Matching (Exact match)
- Fuzzy Matching (Similar match)
- Compare Face (Face comparison)
| Filter Stage | Fields Used | Description |
|---|---|---|
| Exact Matching | Date of birth (birthDate), Gender, Nationality | Searches for users with exactly matching information. |
| Fuzzy Matching | Name | Searches for users with similar names. Allows typos or slight differences. |
| Compare Face | Portrait | Confirms if same person by comparing face images. |
Filter Pass ConditionsWhen a user matching conditions is found at each filter stage, it proceeds to the next stage. Only when all stages are passed is it judged as a duplicate user, so cases where only some information matches are not detected as duplicates.
Default Fields
Default fields used for duplicate checks by pipeline are as follows:| Pipeline | Base Fields |
|---|---|
| ID document | Name, date of birth, gender, nationality, portrait |
| Knowledge-based | Name, date of birth, gender, nationality |
Processing When Duplicate Detected
Select the processing method for submissions detected as duplicates. (Radio button)| Processing Method | Description |
|---|---|
| Approved submission + Duplicate information display | Approves submissions detected as duplicates but displays duplicate information. |
| Reject submission if duplicate | Rejects submissions when detected as duplicates. |
Duplicate Check Pipeline UsageWhen operating a one-person-one-account policy, you can activate the duplicate check pipeline to prevent creating multiple accounts with the same identity information. Selecting both default method and custom DI pipelines enables more accurate duplicate detection.
Submission Rate Limiting
Sets the maximum number of verification attempts a user can make within the same period. Operates in Window Sliding method to effectively block excessive submission attempts by malicious users.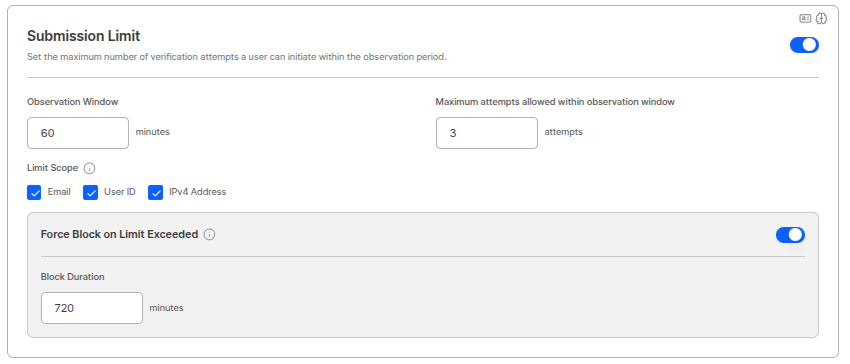
Operation Method (Window Sliding)
Submission rate limiting operates in Window Sliding method. Based on when the last submission came in, it goes back by the set time window (Window) and checks the number of submissions within that period. Operation Principle:- User attempts submission.
- System goes back by the set time window (e.g., 1 hour) from the last submission point.
- Checks the number of submissions within that time window.
- If allowed count is exceeded, blocks authentication for the remaining time of the time window.
Restriction Scope Settings
You can select criteria for detecting submission rate limiting. The following items can be combined:| Criteria | Description |
|---|---|
| Limits based on number of submissions with the same email address. | |
| User ID | Limits based on number of submissions with the same user ID. |
| IPv4 Address | Limits based on number of submissions from the same IPv4 address. |
Restriction Scope CombinationMultiple criteria can be selected simultaneously. For example, if both email and IPv4 address are selected, blocking occurs if either criterion exceeds the allowed count.
Force Block Function
You can effectively block abusers through the force block function when limits are exceeded. Block Period Settings: You can set an additional block period for users who exceed the limit count. During this period, the user cannot attempt authentication. Usage Scenarios:- Abuser Blocking: Block users who continuously attempt submissions for malicious purposes
- Prevent Bad Attempts: Block repeated submission attempts for forgery or fraud purposes
- System Protection: Prevent system load from excessive submissions
Duplicate Approval Prevention Period
Prevents duplicate submissions from already approved users.
Period Settings
Period can be set within 0~365 days range. (Example: 7 days)Duplicate Check Method
Checks for duplicates based on the following items. (Checkboxes)- IP address
- Local storage
- Identity information: name, date of birth, gender, nationality
- Resident registration number
Duplicate Approval Prevention Period UsageIf operating a one-person-one ‘approved’ account policy, be sure to set this function. If there is an approved submission with the same information within the set period, new submissions are rejected.
Duplicate Check Field PrecautionsWhen Identity info and Identity number are set, users submitting identical information are rejected.
Duplicate Rejection Prevention Period
Prevents duplicate submissions from already rejected users.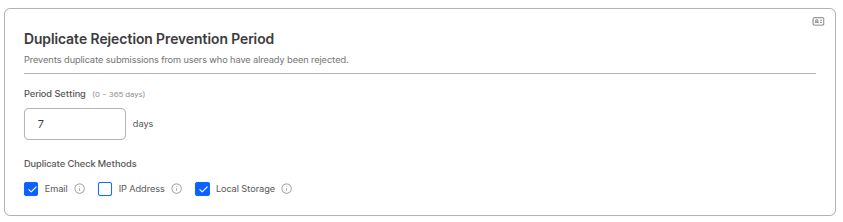
Period Settings
Period can be set within 0~365 days range. (Example: 0 days)Duplicate Check Method
Checks for duplicates based on the following items. (Checkboxes)- IP address
- Local storage
Duplicate Rejection Prevention Period UsageUsed to prevent malicious users from continuously resubmitting with rejected information. Setting the period to 0 days disables this function.
Related Documentation
KYC Process
View basic authentication policies.
Authentication Enhancement and Forgery Prevention
View forgery prevention settings.
Submission List
Learn how to manage submissions.
GET/Submission API
Learn how to use API to query DI values.