> ## Documentation Index
> Fetch the complete documentation index at: https://developers.argosidentity.com/llms.txt
> Use this file to discover all available pages before exploring further.
# 엔진 선택
> Omni 엔진 카탈로그에서 선택하여 검증 워크플로우를 구성합니다.
## 엔진 카탈로그
Omni는 워크플로우 설정 시 선택할 수 있는 AI 기반 MCP 엔진을 제공합니다. 정책을 정의하면 시스템이 검증 단계에 맞는 엔진을 자동으로 제안합니다. Identity Agent(DAG Planner)가 자동으로 오케스트레이션합니다.
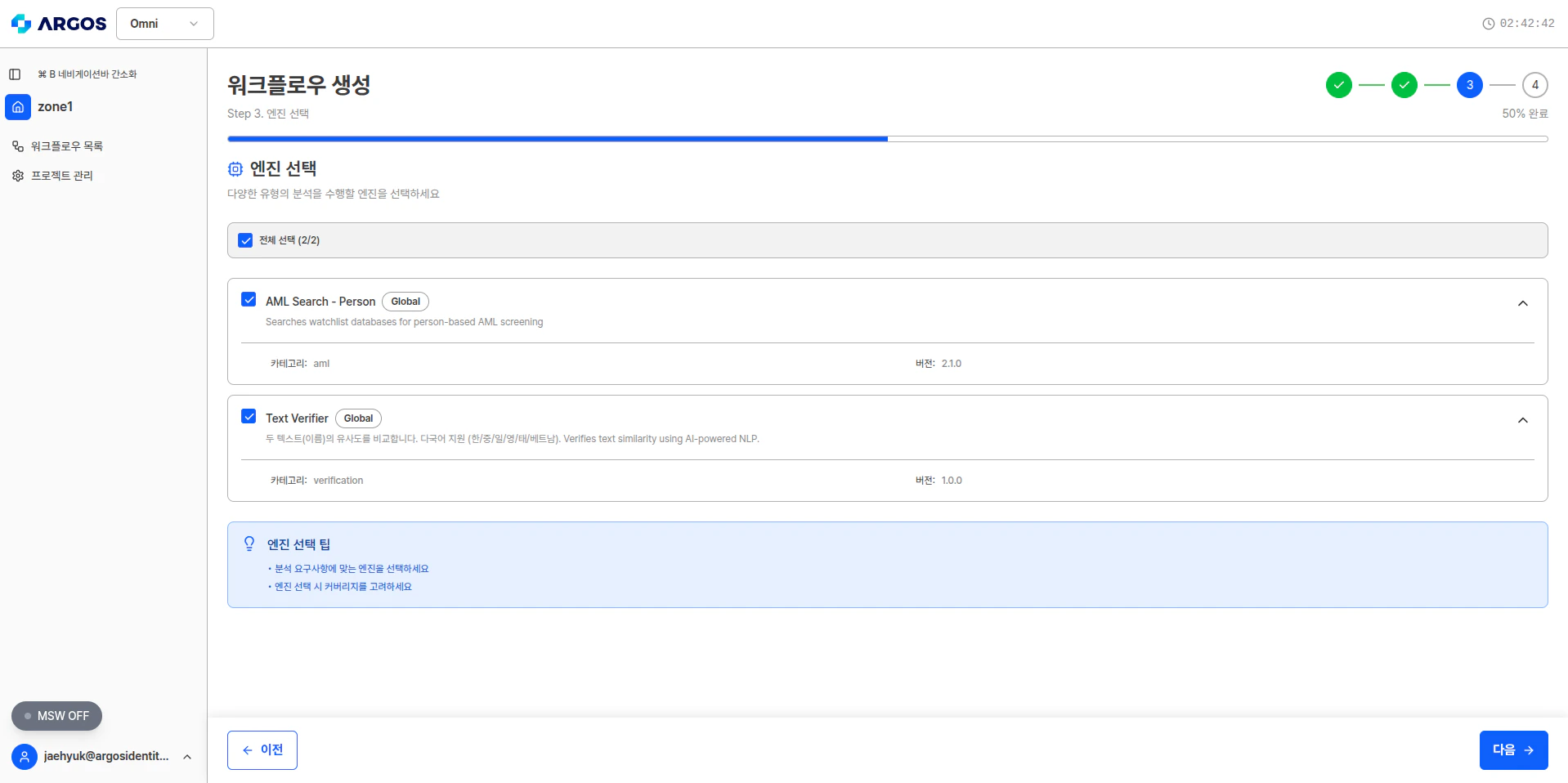
### 제공 엔진
| 엔진 | 유형 | 설명 |
| ------------------------- | ---- | ------------------------------------------- |
| **AML Search - Person** | 스크리닝 | 이름 기반 검색으로 글로벌 AML/제재 감시 목록 대비 개인 스크리닝 |
| **Text Verifier - Glove** | 검증 | AI 기반 텍스트 분석으로 문서 텍스트의 일관성, 정확성, 필드 간 교차 검증 |
 Omni의 기능이 확장됨에 따라 추가 엔진이 지속적으로 추가될 예정입니다. 신분증 파싱, 얼굴 인식, 사업자등록 검증 등 더 다양한 검증 사용 사례를 지원할 계획입니다.
***
## AML Search - Person
AML Search 엔진은 MCP 도구 호출(`search_individual`)을 통해 글로벌 AML/제재 감시 목록 대비 개인을 스크리닝합니다. **외부 데이터베이스 조회**를 수행하는 유일한 엔진입니다.
### 입력
AI 에이전트가 제출된 문서에서 다음 필드를 추출하여 AML Search 엔진에 전달합니다:
| 필드 | 설명 |
| --------------- | -------------------------------- |
| `name` | 인물 이름 (대소문자 구분 없음, 닉네임/별칭 매칭 지원) |
| `date_of_birth` | 생년월일 (가능한 경우, 매칭 정확도 향상) |
| `nationality` | 국적/국가 (가능한 경우, 매칭 정확도 향상) |
### 매칭 점수
최종 매칭 점수는 개별 필드 점수의 평균으로 계산됩니다:
| 필드 | 매칭 방식 | 점수 |
| ---- | ----------------------------- | ------- |
| 이름 | 문자열 거리 알고리즘 + ARGOS 닉네임 라이브러리 | 가변 |
| 생년월일 | 정확 일치 = 100%, 부분 일치 = 80% | 80–100% |
| 국적 | 정확 일치 = 100%, 부분 일치 = 80% | 80–100% |
### 출력 — 위험 아이콘
스크리닝 결과는 다음 위험 아이콘으로 위험 수준별 분류됩니다:
| 위험 아이콘 | 설명 |
| ------------- | --------------------------------- |
| `SAN-CURRENT` | 현재 제재 목록에 등록된 개인 |
| `PEP-CURRENT` | 현재 주요 정치적 역할을 맡고 있는 개인 |
| `REL` | 금융 규제 또는 법 집행 기관의 조치 대상인 개인 또는 단체 |
| 위험 아이콘 | 설명 |
| ------------ | --------------------------------- |
| `PEP-LINKED` | 정치적으로 노출된 인물과 관련된 개인 |
| `PEP-FORMER` | 과거에 정치적 역할을 맡았던 개인 |
| `SAN-FORMER` | 과거 제재 목록에 등록되었던 개인 |
| `POI` | 관심 프로필 — 만료된 PEP 상태 또는 오래된 RRE 기록 |
| 위험 아이콘 | 설명 |
| ------ | --------------------------------- |
| `RRE` | 글로벌 미디어에서 금융 범죄 관련으로 보도된 개인 |
| `INS` | 파산 또는 지급불능 선고를 받은 개인 (영국 및 아일랜드만) |
| `DD` | 회사 이사 자격이 박탈된 개인 (영국만) |
| `GRI` | 강화된 실사(EDD) 요약 보고서 |
### 출력 — 결과 상태
| 상태 | 설명 |
| -------------- | --------------------------- |
| `No Matches` | AML 데이터베이스에서 일치하는 개인을 찾지 못함 |
| `Not Screened` | 스크리닝이 수행되지 않음 |
| `Red Flag` | 고위험 개인 또는 단체 식별 — 추가 검토 필요 |
### 분석 응답 필드
이 엔진이 실행되면 결과는 다음에 표시됩니다:
* `agentAuditLog[].mcpToolCalls[]` — `toolName`(예: `search_individual`), `engineCode`, `engineName`, 파라미터, 매칭 결과가 포함된 `rawContent` 등 원시 MCP 도구 호출 상세 정보
* `findings[]` — `category`, `result` (passed/warning/failed), `details`가 포함된 요약 결과
* `rawActionResults` — 검증 상태가 포함된 액션 결과 텍스트
전체 AML 데이터베이스 소스 문서, 위험 아이콘 상세 설명, 검색 알고리즘 사양은 [AML 데이터베이스 소스 및 코드](/dashboard/ko/aml-source) 참조 문서를 확인하세요.
***
## Text Verifier - Glove
Text Verifier 엔진은 RAG(Retrieval-Augmented Generation) 기반 AI 분석을 통해 문서 텍스트의 일관성, 정확성, 완전성을 검증합니다. 이 엔진은 **외부 데이터베이스 조회를 수행하지 않으며**, 프로필에 업로드된 문서만으로 작업합니다.
### 입력
AI 에이전트가 엔진에 다음을 제공합니다:
| 필드 | 설명 |
| ------ | ---------------------------------------- |
| 문서 | 프로필에 업로드된 모든 아이템 (OCR 또는 직접 읽기로 추출된 텍스트) |
| 정책 지침 | 워크플로우 정책에 정의된 검증 규칙 |
| 출력 스키마 | 채워야 할 예상 결과 구조 |
### 기능
* **데이터 추출** — 문서에서 구조화된 값 추출 (이름, 번호, 날짜, 주소 등)
* **필드 간 교차 검증** — 문서 내 및 문서 간 필드 일관성 확인
* **완전성 검사** — 모든 필수 필드가 존재하고 채워져 있는지 확인
* **문서 유효성** — 문서가 유효하고 변조되지 않았는지 평가
* **정책 준수** — 자연어 정책 규칙에 따라 문서 평가
### 출력
Text Verifier는 분석 응답의 주요 콘텐츠를 생성합니다:
| 출력 섹션 | 설명 |
| ------------------------------------ | -------------------------------------------------------------------- |
| `extractedData.extracted_values` | 문서에서 추출된 원시 값 (필드 이름은 출력 스키마에 의해 정의) |
| `extractedData.category_judgements` | 카테고리별 검증 결과 — `pass` / `fail` / `unverifiable` / `needs_review` 및 사유 |
| `extractedData.document_validations` | 문서 유효성 평가 — `is_valid` (boolean) 및 사유 |
| `extractedData.review_result` | 최종 조치 (`approve` / `reject` / `manual_review`), 위험 수준, 사유 |
### 분석 응답 필드
이 엔진이 실행되면 결과는 다음에 표시됩니다:
* `agentAuditLog[].ragResponse` — 응답 텍스트, 인용, 처리 시간이 포함된 RAG 쿼리 결과
* `findings[]` — 검증 단계별 요약 결과
* `extractedData` — 출력 스키마를 따르는 전체 구조화된 출력
* `rawActionResults` — 액션별 결과 텍스트 및 검증 상태
`extractedData` 내부의 필드는 워크플로우의 **[출력 스키마](/ko/omni/dashboard/workflow-setup/output-schema)** 설정에 의해 결정됩니다. 위의 섹션(extracted\_values, category\_judgements 등)은 일반적인 패턴이며, 실제 필드 이름은 스키마 정의에 따라 달라집니다.
***
## 엔진 선택 방식
정책을 정의하면 Omni가 검증 단계에 따라 엔진을 제안합니다. 수동으로 엔진을 추가하거나 제거할 수도 있습니다.
Identity Agent가 선택된 엔진의 **실행 순서**를 자동으로 결정합니다. 수동으로 종속성을 설정할 필요가 없습니다 — DAG Planner가 오케스트레이션을 처리합니다.
## 워크플로우 템플릿
사전 구성된 엔진 조합이 [워크플로우 템플릿](/ko/omni/guides/workflow-templates)으로 제공됩니다. 일반적인 사용 사례를 위한 권장 시작점을 제공합니다.
Omni의 기능이 확장됨에 따라 추가 엔진이 지속적으로 추가될 예정입니다. 신분증 파싱, 얼굴 인식, 사업자등록 검증 등 더 다양한 검증 사용 사례를 지원할 계획입니다.
***
## AML Search - Person
AML Search 엔진은 MCP 도구 호출(`search_individual`)을 통해 글로벌 AML/제재 감시 목록 대비 개인을 스크리닝합니다. **외부 데이터베이스 조회**를 수행하는 유일한 엔진입니다.
### 입력
AI 에이전트가 제출된 문서에서 다음 필드를 추출하여 AML Search 엔진에 전달합니다:
| 필드 | 설명 |
| --------------- | -------------------------------- |
| `name` | 인물 이름 (대소문자 구분 없음, 닉네임/별칭 매칭 지원) |
| `date_of_birth` | 생년월일 (가능한 경우, 매칭 정확도 향상) |
| `nationality` | 국적/국가 (가능한 경우, 매칭 정확도 향상) |
### 매칭 점수
최종 매칭 점수는 개별 필드 점수의 평균으로 계산됩니다:
| 필드 | 매칭 방식 | 점수 |
| ---- | ----------------------------- | ------- |
| 이름 | 문자열 거리 알고리즘 + ARGOS 닉네임 라이브러리 | 가변 |
| 생년월일 | 정확 일치 = 100%, 부분 일치 = 80% | 80–100% |
| 국적 | 정확 일치 = 100%, 부분 일치 = 80% | 80–100% |
### 출력 — 위험 아이콘
스크리닝 결과는 다음 위험 아이콘으로 위험 수준별 분류됩니다:
| 위험 아이콘 | 설명 |
| ------------- | --------------------------------- |
| `SAN-CURRENT` | 현재 제재 목록에 등록된 개인 |
| `PEP-CURRENT` | 현재 주요 정치적 역할을 맡고 있는 개인 |
| `REL` | 금융 규제 또는 법 집행 기관의 조치 대상인 개인 또는 단체 |
| 위험 아이콘 | 설명 |
| ------------ | --------------------------------- |
| `PEP-LINKED` | 정치적으로 노출된 인물과 관련된 개인 |
| `PEP-FORMER` | 과거에 정치적 역할을 맡았던 개인 |
| `SAN-FORMER` | 과거 제재 목록에 등록되었던 개인 |
| `POI` | 관심 프로필 — 만료된 PEP 상태 또는 오래된 RRE 기록 |
| 위험 아이콘 | 설명 |
| ------ | --------------------------------- |
| `RRE` | 글로벌 미디어에서 금융 범죄 관련으로 보도된 개인 |
| `INS` | 파산 또는 지급불능 선고를 받은 개인 (영국 및 아일랜드만) |
| `DD` | 회사 이사 자격이 박탈된 개인 (영국만) |
| `GRI` | 강화된 실사(EDD) 요약 보고서 |
### 출력 — 결과 상태
| 상태 | 설명 |
| -------------- | --------------------------- |
| `No Matches` | AML 데이터베이스에서 일치하는 개인을 찾지 못함 |
| `Not Screened` | 스크리닝이 수행되지 않음 |
| `Red Flag` | 고위험 개인 또는 단체 식별 — 추가 검토 필요 |
### 분석 응답 필드
이 엔진이 실행되면 결과는 다음에 표시됩니다:
* `agentAuditLog[].mcpToolCalls[]` — `toolName`(예: `search_individual`), `engineCode`, `engineName`, 파라미터, 매칭 결과가 포함된 `rawContent` 등 원시 MCP 도구 호출 상세 정보
* `findings[]` — `category`, `result` (passed/warning/failed), `details`가 포함된 요약 결과
* `rawActionResults` — 검증 상태가 포함된 액션 결과 텍스트
전체 AML 데이터베이스 소스 문서, 위험 아이콘 상세 설명, 검색 알고리즘 사양은 [AML 데이터베이스 소스 및 코드](/dashboard/ko/aml-source) 참조 문서를 확인하세요.
***
## Text Verifier - Glove
Text Verifier 엔진은 RAG(Retrieval-Augmented Generation) 기반 AI 분석을 통해 문서 텍스트의 일관성, 정확성, 완전성을 검증합니다. 이 엔진은 **외부 데이터베이스 조회를 수행하지 않으며**, 프로필에 업로드된 문서만으로 작업합니다.
### 입력
AI 에이전트가 엔진에 다음을 제공합니다:
| 필드 | 설명 |
| ------ | ---------------------------------------- |
| 문서 | 프로필에 업로드된 모든 아이템 (OCR 또는 직접 읽기로 추출된 텍스트) |
| 정책 지침 | 워크플로우 정책에 정의된 검증 규칙 |
| 출력 스키마 | 채워야 할 예상 결과 구조 |
### 기능
* **데이터 추출** — 문서에서 구조화된 값 추출 (이름, 번호, 날짜, 주소 등)
* **필드 간 교차 검증** — 문서 내 및 문서 간 필드 일관성 확인
* **완전성 검사** — 모든 필수 필드가 존재하고 채워져 있는지 확인
* **문서 유효성** — 문서가 유효하고 변조되지 않았는지 평가
* **정책 준수** — 자연어 정책 규칙에 따라 문서 평가
### 출력
Text Verifier는 분석 응답의 주요 콘텐츠를 생성합니다:
| 출력 섹션 | 설명 |
| ------------------------------------ | -------------------------------------------------------------------- |
| `extractedData.extracted_values` | 문서에서 추출된 원시 값 (필드 이름은 출력 스키마에 의해 정의) |
| `extractedData.category_judgements` | 카테고리별 검증 결과 — `pass` / `fail` / `unverifiable` / `needs_review` 및 사유 |
| `extractedData.document_validations` | 문서 유효성 평가 — `is_valid` (boolean) 및 사유 |
| `extractedData.review_result` | 최종 조치 (`approve` / `reject` / `manual_review`), 위험 수준, 사유 |
### 분석 응답 필드
이 엔진이 실행되면 결과는 다음에 표시됩니다:
* `agentAuditLog[].ragResponse` — 응답 텍스트, 인용, 처리 시간이 포함된 RAG 쿼리 결과
* `findings[]` — 검증 단계별 요약 결과
* `extractedData` — 출력 스키마를 따르는 전체 구조화된 출력
* `rawActionResults` — 액션별 결과 텍스트 및 검증 상태
`extractedData` 내부의 필드는 워크플로우의 **[출력 스키마](/ko/omni/dashboard/workflow-setup/output-schema)** 설정에 의해 결정됩니다. 위의 섹션(extracted\_values, category\_judgements 등)은 일반적인 패턴이며, 실제 필드 이름은 스키마 정의에 따라 달라집니다.
***
## 엔진 선택 방식
정책을 정의하면 Omni가 검증 단계에 따라 엔진을 제안합니다. 수동으로 엔진을 추가하거나 제거할 수도 있습니다.
Identity Agent가 선택된 엔진의 **실행 순서**를 자동으로 결정합니다. 수동으로 종속성을 설정할 필요가 없습니다 — DAG Planner가 오케스트레이션을 처리합니다.
## 워크플로우 템플릿
사전 구성된 엔진 조합이 [워크플로우 템플릿](/ko/omni/guides/workflow-templates)으로 제공됩니다. 일반적인 사용 사례를 위한 권장 시작점을 제공합니다.