> ## Documentation Index
> Fetch the complete documentation index at: https://developers.argosidentity.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Output schema
> Defina la estructura JSON de sus resultados de verificación con output schemas personalizados.
## ¿Qué es un output schema?
Un output schema define la **estructura JSON exacta** de los resultados devueltos por Omni. En lugar de recibir salidas crudas de los engines, obtiene resultados formateados exactamente como los necesitan sus sistemas.
## Cómo definir un output schema
Los output schemas se definen como estructuras JSON dentro de la configuración del workflow. Cada campo se asigna a datos extraídos y verificados por los engines del workflow.
### Guía de escritura del schema
Cuando configure el output schema en el **Step 4** de creación del workflow, la UI aplica estas reglas:
* **Standard**: sigue [JSON Schema Draft-07](https://json-schema.org/draft-07/json-schema-release-notes.html) con restricciones adicionales de Omni.
* **Root shape**: debe empezar con `"type": "object"` y definir campos bajo `"properties"`.
* **Field types**: puede usar `string`, `number`, `integer`, `boolean`, `object` y `array`.
* **Nesting depth**: la anidación está limitada a **2 niveles**.
* **Duplicate names**: no se permiten nombres de campo duplicados.
* **`description`**: añadir `description` en cada campo mejora la precisión de la IA.
* **Sync**: **Field Builder** y **JSON input** se sincronizan automáticamente.
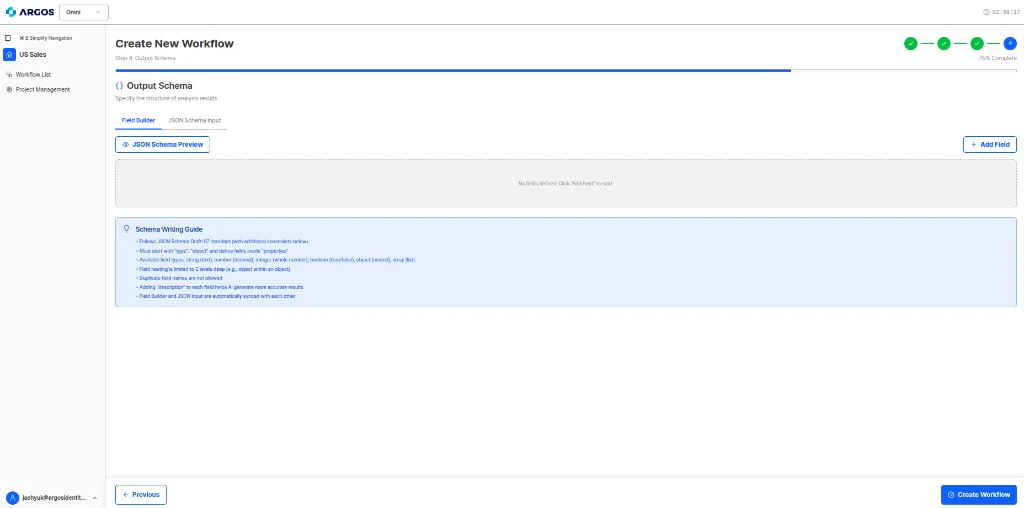
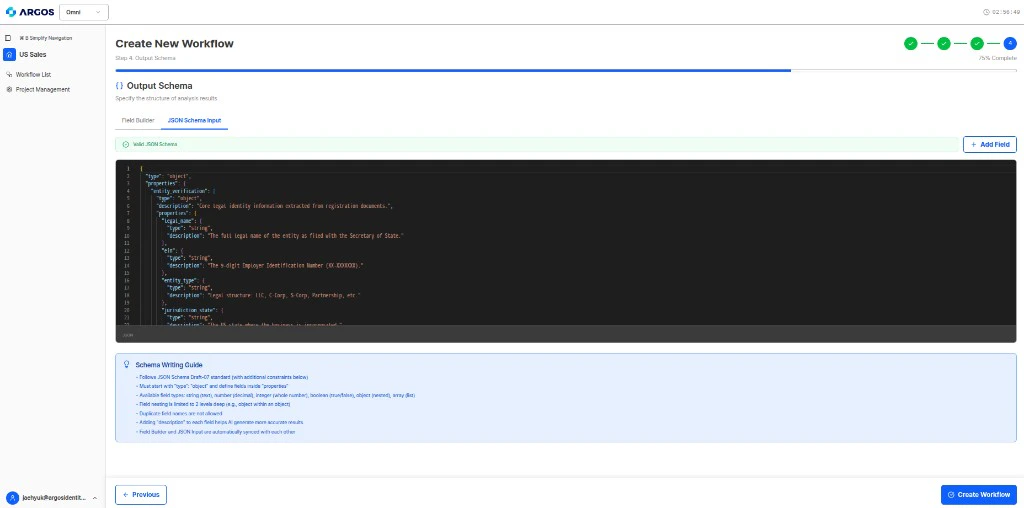 **Ejemplo de output schema para KYB:**
```json theme={null}
{
"company": {
"name": "string",
"registrationNumber": "string",
"country": "string",
"incorporationDate": "string",
"directors": ["string"]
},
"verification": {
"amlScreeningResult": "string",
"registrationValid": "boolean",
"beneficialOwnership": "string"
},
"decision": {
"result": "APPROVE | REJECT | FLAG",
"verificationStatus": "pending_review | approved | rejected",
"flagReasons": ["string"]
}
}
```
## Verification status
La respuesta de análisis expone un único **`verificationStatus`** con uno de estos valores: `pending_review`, `approved` o `rejected`. Modele su bloque **decision** para que sus sistemas downstream puedan usar ese mismo enum.
| Valor | Uso habitual |
| ---------------- | ------------------------- |
| `approved` | Aceptación automática |
| `pending_review` | Envío a revisión humana |
| `rejected` | Rechazo o fallo de policy |
## Buenas prácticas
Diseñe el schema para que coincida con lo que esperan su backend o sus sistemas de compliance. Así evita transformaciones posteriores.
Añada siempre un bloque superior con `result`, `verificationStatus` y razones. Esto facilita el routing automatizado.
Los schemas simples son más fáciles de mantener e integrar. Anide solo cuando los datos realmente lo requieran.
## Ontology Mapper
El Ontology Mapper valida que las salidas de los engines se ajusten al schema definido. Si un engine devuelve datos en un formato distinto, el mapper los normaliza antes de entregarlos.
**Ejemplo de output schema para KYB:**
```json theme={null}
{
"company": {
"name": "string",
"registrationNumber": "string",
"country": "string",
"incorporationDate": "string",
"directors": ["string"]
},
"verification": {
"amlScreeningResult": "string",
"registrationValid": "boolean",
"beneficialOwnership": "string"
},
"decision": {
"result": "APPROVE | REJECT | FLAG",
"verificationStatus": "pending_review | approved | rejected",
"flagReasons": ["string"]
}
}
```
## Verification status
La respuesta de análisis expone un único **`verificationStatus`** con uno de estos valores: `pending_review`, `approved` o `rejected`. Modele su bloque **decision** para que sus sistemas downstream puedan usar ese mismo enum.
| Valor | Uso habitual |
| ---------------- | ------------------------- |
| `approved` | Aceptación automática |
| `pending_review` | Envío a revisión humana |
| `rejected` | Rechazo o fallo de policy |
## Buenas prácticas
Diseñe el schema para que coincida con lo que esperan su backend o sus sistemas de compliance. Así evita transformaciones posteriores.
Añada siempre un bloque superior con `result`, `verificationStatus` y razones. Esto facilita el routing automatizado.
Los schemas simples son más fáciles de mantener e integrar. Anide solo cuando los datos realmente lo requieran.
## Ontology Mapper
El Ontology Mapper valida que las salidas de los engines se ajusten al schema definido. Si un engine devuelve datos en un formato distinto, el mapper los normaliza antes de entregarlos.